п°п╣я┌п╬п╢ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫я▀я┘
п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬-я┐п©я─п╟п╡п╩я▐я▌я┴п╦я┘ я│п╦я│я┌п╣п╪ п╫п╟ п╬я│п╫п╬п╡п╣ я│я┌п╟п╫п╢п╟я─я┌п╟ XML
{kind=link}
14027, п╖п╣я─п╫п╦пЁп╬п╡-27, я┐п╩. п╗п╣п╡я┤п╣п╫п╨п╬, 95
я┌.(0462)101577, я└п╟п╨я│. (0462)958751
e-mail: vlad@cg.ukrtel.net A.Pastukhov@itek.com.ua
п▓ я│я┌п╟я┌я▄п╣ я─п╟я│я│п╪п╟я┌я─п╦п╡п╟п╣я┌я│я▐ п╪п╣я┌п╬п╢ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫я▀я┘ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬-я┐п©я─п╟п╡п╩я▐я▌я┴п╦я┘ я│п╦я│я┌п╣п╪, п╬я│п╫п╬п╡п╟п╫п╫я▀п╧ п╫п╟ я│п╬п╡п╪п╣я│я┌п╫п╬п╪ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╦ XML п╦ XSL п╡ я─п╟п╪п╨п╟я┘ п╣п╢п╦п╫п╬п╧ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ п╪п╬п╢п╣п╩п╦. п÷я─п╦п╡п╬п╢п╦я┌я│я▐ п╬п©п╦я│п╟п╫п╦п╣ я█я┌п╟п©п╬п╡ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ п╫п╟ п©я─п╦п╪п╣я─п╣ я─п╟я│я│п╪п╬я┌я─п╣п╫п╦я▐ я┐п©я─п╬я┴п╣п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─я▀ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╟ я┌п╟п╨п╤п╣ п╟п╫п╟п╩п╦п╥п╦я─я┐я▌я┌я│я▐ я─п╣п╥я┐п╩я▄я┌п╟я┌я▀ п©я─п╟п╨я┌п╦я┤п╣я│п╨п╬пЁп╬ п©я─п╦п╪п╣п╫п╣п╫п╦я▐ п╢п╟п╫п╫п╬пЁп╬ п╪п╣я┌п╬п╢п╟ п©я─п╦ я─п╟п╥я─п╟п╠п╬я┌п╨п╣ я│п╩п╬п╤п╫п╬п╧ я│п╦я│я┌п╣п╪я▀ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ п©я─п╬п╣п╨я┌п╟п╪п╦.
In this article, the method of designing of the Internet-focused information control systems, based on sharing XML and XSL is considered within the framework of uniform information model. The description of design stages is resulted on an example of the simplified document structure, and also results of practical application of the given method are analyzed by development of the complexб═ project management system.
п▓п╡п╣п╢п╣п╫п╦п╣
п▒п╩п╟пЁп╬п╢п╟я─я▐ я│п╡п╬п╦п╪ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╪ п╡п╬п╥п╪п╬п╤п╫п╬я│я┌я▐п╪ Internet п╡я│п╣ п╡ п╠п╬п╩я▄я┬п╣п╧ я│я┌п╣п©п╣п╫п╦ п©я─п╬п╫п╦п╨п╟п╣я┌ п╡ я│я└п╣я─я▀ я┐п©я─п╟п╡п╩п╣п╫п╦я▐. п·я│п╬п╠п╬ п╡я▀я│п╬п╨п╟ п╣пЁп╬ я─п╬п╩я▄ п©я─п╦ п©п╬я│я┌я─п╬п╣п╫п╦п╦ я─п╟я│п©я─п╣п╢п╣п╩п╣п╫п╫я▀я┘ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬-я┐п©я─п╟п╡п╩я▐я▌я┴п╦я┘ я│п╦я│я┌п╣п╪ (п═п≤пёп║). п÷я─п╦ п╡я│п╣п╪ я─п╟п╥п╫п╬п╬п╠я─п╟п╥п╦п╦ п╦ я│п╩п╬п╤п╫п╬я│я┌п╦ я─п╣я┬п╟п╣п╪я▀я┘ п╢п╟п╫п╫я▀п╪п╦ я│п╦я│я┌п╣п╪п╟п╪п╦ п╥п╟п╢п╟я┤, п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╣ Internet п©п╬п╥п╡п╬п╩я▐п╣я┌ я─п╣п╟п╩я▄п╫п╬ п©п╬п╢п╬п╧я┌п╦ п╨ п╬я│я┐я┴п╣я│я┌п╡п╩п╣п╫п╦я▌ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ я─п╟п╥п╫п╬я─п╬п╢п╫я▀п╪п╦ я─п╟я│п©я─п╣п╢п╣п╩п╣п╫п╫я▀п╪п╦ я─п╣я│я┐я─я│п╟п╪п╦ я│ я┐я┤п╣я┌п╬п╪ п╦я┘ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫я▀я┘ п©п╬я┌я─п╣п╠п╫п╬я│я┌п╣п╧. п·я│п╫п╬п╡п╬п╧ я┌п╟п╨п╬пЁп╬ я─п╬п╢п╟ я─п╣я┬п╣п╫п╦п╧ п╪п╬пЁя┐я┌ я│п╩я┐п╤п╦я┌я▄ я┐п╤п╣ я│я┐я┴п╣я│я┌п╡я┐я▌я┴п╦п╣ я│я┌п╟п╫п╢п╟я─я┌я▀ п╦ я┌п╣я┘п╫п╬п╩п╬пЁп╦п╦, я─п╟п╥я─п╟п╠п╬я┌п╟п╫п╫я▀п╣ п╨п╟п╨ п╫п╣п©п╬я│я─п╣п╢я│я┌п╡п╣п╫п╫п╬ п╢п╩я▐ я│п╣я┌п╦ Internet, я┌п╟п╨ п╦ п╦я│п©п╬п╩я▄п╥я┐п╣п╪я▀п╣ п╡ п╫п╣п╧.
п²п╟п╦п╠п╬п╩п╣п╣ я▐я─п╨п╬ п╦п╢п╣я▐ п╨п╬я─п©п╬я─п╟я┌п╦п╡п╫п╬пЁп╬ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ п╫п╟ п╠п╟п╥п╣ Web п╡я▀я─п╟п╤п╣п╫п╟ п╡ п╦п╫п╦я├п╦п╟я┌п╦п╡п╣ Microsoft, Cisco Systems, Compaq Computer, BMC Software п╦ Intel, п╨п╬я┌п╬я─я▀п╣ п╡я▀п╢п╡п╦п╫я┐п╩п╦ п©п╩п╟п╫ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦я▐ я│я┌п╟п╫п╢п╟я─я┌п╦п╥п╬п╡п╟п╫п╫я▀я┘ я┌п╣я┘п╫п╬п╩п╬пЁп╦п╧ п╡п╥п╟п╦п╪п╬п╢п╣п╧я│я┌п╡п╦я▐ п╦ п╥п╟я┴п╦я┌я▀ Web п╢п╩я▐ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ я│п╦я│я┌п╣п╪п╟п╪п╦ п╦ я│п╣я┌я▐п╪п╦ п╡ я─п╟п╪п╨п╟я┘ Web-based Enterprise Management (WBEM) [1]. п║я─п╣п╢п╦ п╬я│п╫п╬п╡п╫я▀я┘ п╨п╬п╪п©п╬п╫п╣п╫я┌п╬п╡ WBEM, п╨ п╨п╬я┌п╬я─я▀п╪ п╬я┌п╫п╬я│я▐я┌я│я▐ п╬п╠я┴п╟я▐ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╟я▐ п╪п╬п╢п╣п╩я▄ (Common Information Model, CIM), HTTP - я┐п╫п╦п╡п╣я─я│п╟п╩я▄п╫я▀п╧ я┌я─п╟п╫я│п©п╬я─я┌п╫я▀п╧ п©я─п╬я┌п╬п╨п╬п╩ п╢п╩я▐ п©п╣я─п╣п╢п╟я┤п╦ п╦п╫я└п╬я─п╪п╟я├п╦п╦ п╡ я│п╣я┌п╦ Internet п╦ я─п╟я│я┬п╦я─я▐п╣п╪я▀п╧ я▐п╥я▀п╨ я─п╟п╥п╪п╣я┌п╨п╦ (Extensible Markup Language, XML), п©п╬я│п╩п╣п╢п╫п╦п╧ п╥п╟п╫п╦п╪п╟п╣я┌ п╬я│п╬п╠п╬п╣ п╪п╣я│я┌п╬.
XML п©я─п╣п╢я│я┌п╟п╡п╩я▐п╣я┌ я│п╬п╠п╬п╧ п©я─п╬я│я┌п╬п╣ п╦ п╡ я┌п╬ п╤п╣ п╡я─п╣п╪я▐ п╪п╬я┴п╫п╬п╣ я│я─п╣п╢я│я┌п╡п╬ я│п╬п╥п╢п╟п╫п╦я▐ я┌п╬п╧ п©п╬п╩п╣п╥п╫п╬п╧ п╫п╟пЁя─я┐п╥п╨п╦, п╨п╬я┌п╬я─я┐я▌ HTTP п╪п╬п╤п╣я┌ п©п╣я─п╣п╢п╟я┌я▄ п╦п╥ п╬п╢п╫п╬пЁп╬ п©я─п╦п╩п╬п╤п╣п╫п╦я▐ п╡ п╢я─я┐пЁп╬п╣, п╦п╥ п╠я─п╟я┐п╥п╣я─п╟ п╡ п©я─п╦п╩п╬п╤п╣п╫п╦п╣ п╦ п╫п╟п╬п╠п╬я─п╬я┌. п÷я─п╦я┤п╣п╪ п╫п╟п╦п╠п╬п╩п╣п╣ п╡п╟п╤п╫п╟я▐ п╬я│п╬п╠п╣п╫п╫п╬я│я┌я▄ XML п╦ я│п╬п©я┐я┌я│я┌п╡я┐я▌я┴п╣п╧ п╣п╪я┐ я┌п╣я┘п╫п╬п╩п╬пЁп╦п╦ я─п╟я│я┬п╦я─я▐п╣п╪п╬пЁп╬ я▐п╥я▀п╨п╟ я┌п╟п╠п╩п╦я├я▀ я│я┌п╦п╩п╣п╧ (Extensible Stylesheet Language, XSL) я│п╬я│я┌п╬п╦я┌ п╡ п╬я┌п╢п╣п╩п╣п╫п╦п╦ я└п╬я─п╪п╟я┌п╦я─п╬п╡п╟п╫п╦я▐ п╬я┌ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬пЁп╬ п╫п╟п©п╬п╩п╫п╣п╫п╦я▐ [2].
п▓ я─п╟п╥п╡п╦я┌п╦п╣ п╦п╢п╣п╦ WBEM п╡ п╢п╟п╫п╫п╬п╧ я│я┌п╟я┌я▄п╣ п©я─п╣п╢п╩п╟пЁп╟п╣я┌я│я▐ п╪п╣я┌п╬п╢ я─п╟п╥я─п╟п╠п╬я┌п╨п╦ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫я▀я┘ п═п≤пёп║, п╬я│п╫п╬п╡п╟п╫п╫я▀п╧ п╫п╟ я│п╬п╡п╪п╣я│я┌п╫п╬п╪ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╦ XML п╦ XSL п╡ я─п╟п╪п╨п╟я┘ п╣п╢п╦п╫п╬п╧ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ п╪п╬п╢п╣п╩п╦. п╒п╟п╨п╬п╧ п©п╬п╢я┘п╬п╢ п©п╬п╥п╡п╬п╩я▐п╣я┌, п©я─п╣п╤п╢п╣ п╡я│п╣пЁп╬, я│п╬я│я─п╣п╢п╬я┌п╬я┤п╦я┌я▄ п╡п╫п╦п╪п╟п╫п╦п╣ п╫п╟ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦п╦ я│п╦я│я┌п╣п╪я▀, п╡п╫я┐я┌я─п╣п╫п╫я▐я▐ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╟я▐ я│я┌я─я┐п╨я┌я┐я─п╟ п╨п╬я┌п╬я─п╬п╧ п©я─п╣п╢я│я┌п╟п╡п╩я▐п╣я┌я│я▐ п╡ п╡п╦п╢п╣ я│я┌я─я┐п╨я┌я┐я─п╦я─п╬п╡п╟п╫п╫я▀я┘ п╬п©я─п╣п╢п╣п╩п╣п╫п╫я▀п╪ п╬п╠я─п╟п╥п╬п╪ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡.
п▓ я│я┌п╟я┌я▄п╣ п©я─п╦п╡п╬п╢п╦я┌я│я▐ п╬п©п╦я│п╟п╫п╦п╣ п©я─п╣п╢п╩п╟пЁп╟п╣п╪п╬пЁп╬ п╪п╣я┌п╬п╢п╟ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ п═п≤пёп║ п╫п╟ п©я─п╦п╪п╣я─п╣ я│п╬п╥п╢п╟п╫п╦я▐ я│п╦я│я┌п╣п╪я▀ я┐п©я─п╬я┴п╣п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─я▀, п╟ я┌п╟п╨п╤п╣ п╟п╫п╟п╩п╦п╥п╦я─я┐я▌я┌я│я▐ я─п╣п╥я┐п╩я▄я┌п╟я┌я▀ п©я─п╟п╨я┌п╦я┤п╣я│п╨п╬пЁп╬ п©я─п╦п╪п╣п╫п╣п╫п╦я▐ п╢п╟п╫п╫п╬пЁп╬ п╪п╣я┌п╬п╢п╟ п©я─п╦ я─п╟п╥я─п╟п╠п╬я┌п╨п╣ я│п╩п╬п╤п╫п╬п╧ я─п╟я│п©я─п╣п╢п╣п╩п╣п╫п╫п╬п╧ я│п╦я│я┌п╣п╪я▀ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ п©я─п╬п╣п╨я┌п╟п╪п╦.
п·п©я─п╣п╢п╣п╩п╣п╫п╦п╣ XML-я│я┌я─я┐п╨я┌я┐я─я▀ п═п≤пёп║
п²п╟п╦п╠п╬п╩п╣п╣ я█я└я└п╣п╨я┌п╦п╡п╫я▀п╪ п©я┐я┌п╣п╪ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ я│п╦я│я┌п╣п╪я▀ я▐п╡п╩я▐п╣я┌я│я▐ п╠я▀я│я┌я─п╬п╣ я│п╬п╥п╢п╟п╫п╦п╣ я─п╟п╠п╬я┌п╟я▌я┴п╣пЁп╬ п©я─п╬я┌п╬я┌п╦п©п╟ я│ п©п╬я│п╩п╣п╢я┐я▌я┴п╦п╪ п╣пЁп╬ я│п╬п╡п╣я─я┬п╣п╫я│я┌п╡п╬п╡п╟п╫п╦п╣п╪. п■п╩я▐ я┐я│п╨п╬я─п╣п╫п╦я▐ я│п╬п╥п╢п╟п╫п╦я▐ я─п╟п╠п╬я┤п╣пЁп╬ п©я─п╬я┌п╬я┌п╦п©п╟ п╡ я─п╟п╪п╨п╟я┘ я─п╟я│я│п╪п╟я┌я─п╦п╡п╟п╣п╪п╬пЁп╬ п╪п╣я┌п╬п╢п╟ я│п╦я│я┌п╣п╪п╟ п╡я─я┐я┤п╫я┐я▌ п╪п╬п╤п╣я┌ п╠я▀я┌я▄ п╥п╟п©п╬п╩п╫п╣п╫п╟ п©я─п╦п╪п╣я─п╫я▀п╪п╦ п╡п╟я─п╦п╟п╫я┌п╟п╪п╦ я┌я─п╣п╠я┐п╣п╪я▀я┘ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╢п╩я▐ п╨п╬я┌п╬я─я▀я┘ п╬п©я─п╣п╢п╣п╩я▐я▌я┌я│я▐ п╦я┘ п╡п╦п╥я┐п╟п╩я▄п╫я▀п╣ п©я─п╣п╢я│я┌п╟п╡п╩п╣п╫п╦я▐ я│ п©п╬п╪п╬я┴я▄я▌ XSLT (Extensible Stylesheet Language Transform) [3]. п÷я─п╦п╪п╣п╫п╣п╫п╦п╣ XML я│я┌п╟п╫п╢п╟я─я┌п╟ п©п╬п╥п╡п╬п╩я▐п╣я┌ п╫п╟ п╫п╟я┤п╟п╩я▄п╫п╬п╪ я█я┌п╟п©п╣ п╬п©я─п╣п╢п╣п╩я▐я┌я▄ я┌п╬п╩я▄п╨п╬ п╬я│п╫п╬п╡п╫я▀п╣ я┌п╣пЁп╦, я│п╬п╢п╣я─п╤п╟я┴п╦п╣ п╨п╩я▌я┤п╣п╡я▀п╣ п╢п╟п╫п╫я▀п╣. п■п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я▀п╣ я┌п╣пЁп╦, я│п╬п╢п╣я─п╤п╟я┴п╦п╣ п╡я│п©п╬п╪п╬пЁп╟я┌п╣п╩я▄п╫я▀п╣ п╢п╟п╫п╫я▀п╣, п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п╢п╬п╬п©я─п╣п╢п╣п╩п╣п╫я▀ п©п╬п╥п╤п╣ п╡ я┘п╬п╢п╣ п©я─п╬я├п╣я│я│п╟ п╡я▀п╢п╣п╩п╣п╫п╦я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╦ п╬п©я┌п╦п╪п╦п╥п╟я├п╦п╦ п╦я┘ я│я┌я─я┐п╨я┌я┐я─я▀.
п═п╟я│я│п╪п╟я┌я─п╦п╡п╟п╣п╪я▀п╧ п╪п╣я┌п╬п╢ я┐п╢п╬п╠п╫п╬ п©п╬я▐я│п╫п╦я┌я▄ п╫п╟ п╫п╣п╠п╬п╩я▄я┬п╬п╪ п©я─п╦п╪п╣я─п╣. п≈п╟п╪п╣я┌п╦п╪, я┤я┌п╬ п©я─п╣п╢п╩п╟пЁп╟п╣п╪я▀п╧ я┐п©я─п╬я┴п╣п╫п╫я▀п╧ п©я─п╦п╪п╣я─ п╫п╣ п╦п╪п╣п╣я┌ п╫п╦я┤п╣пЁп╬ п╬п╠я┴п╣пЁп╬ я│ я─п╣п╟п╩я▄п╫п╬п╧ я│п╦я│я┌п╣п╪п╬п╧, я│п╬п╥п╢п╟п╫п╫п╬п╧ я│ п©п╬п╪п╬я┴я▄я▌ п╢п╟п╫п╫п╬пЁп╬ п╪п╣я┌п╬п╢п╟, п╦ я│п╩я┐п╤п╦я┌ я┌п╬п╩я▄п╨п╬ п╢п╩я▐ п╬п╠п╣я│п©п╣я┤п╣п╫п╦я▐ п╠п╬п╩я▄я┬п╣п╧ п╫п╟пЁп╩я▐п╢п╫п╬я│я┌п╦.
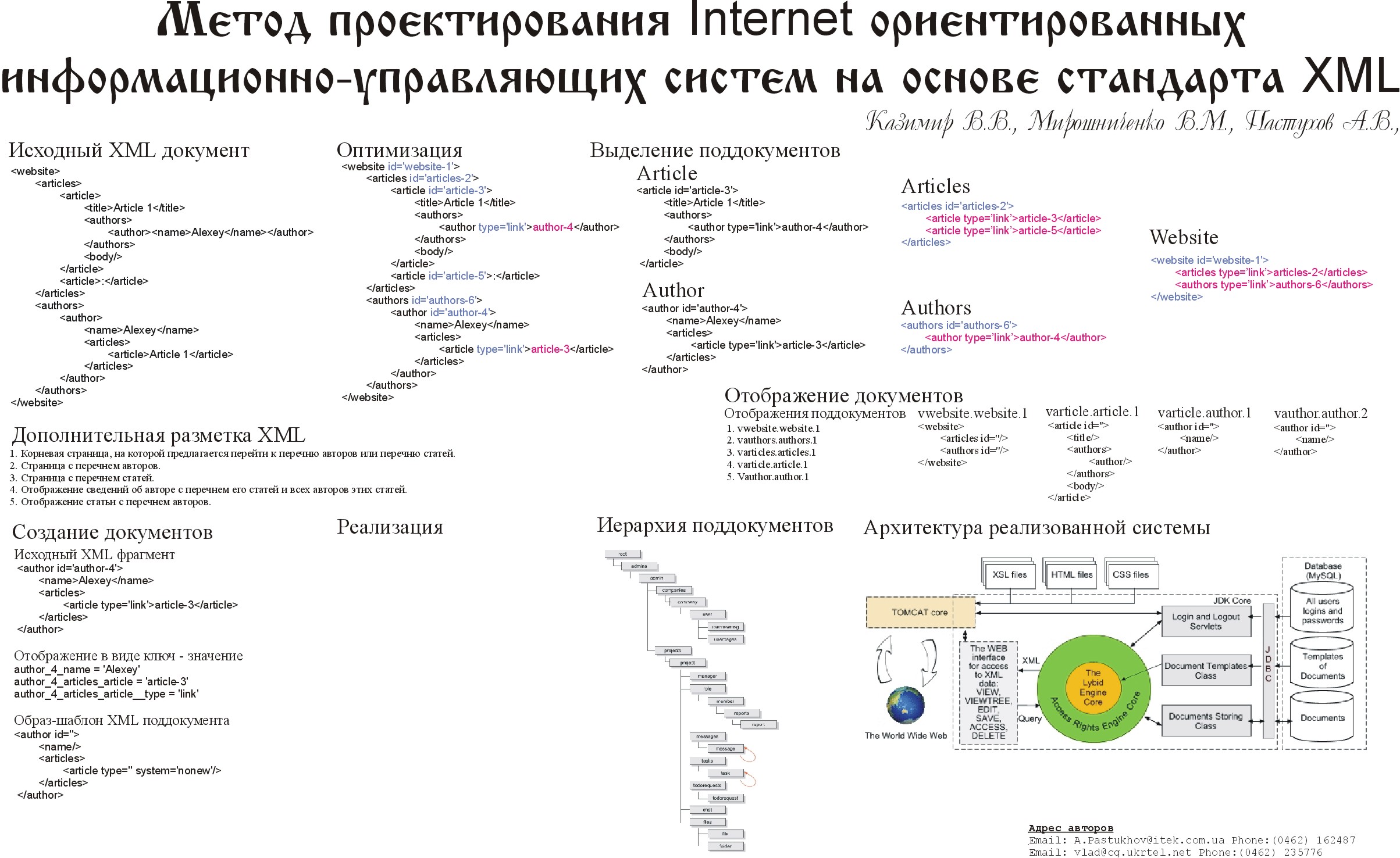
п■п╬п©я┐я│я┌п╦п╪, я┤я┌п╬ п©я─п╬п╣п╨я┌п╦я─я┐п╣п╪п╟я▐ я│п╦я│я┌п╣п╪п╟ п╢п╬п╩п╤п╫п╟ я│п╬п╢п╣я─п╤п╟я┌я▄ п╫п╣п╨п╬я┌п╬я─я▀п╣ я│п╡п╣п╢п╣п╫п╦я▐ п╬ п©я┐п╠п╩п╦п╨п╟я├п╦я▐я┘ п╦ п╦я┘ п╟п╡я┌п╬я─п╟я┘. п▒п╟п╥п╬п╡я▀п╧ XML п╢п╬п╨я┐п╪п╣п╫я┌ я┌п╟п╨п╬п╧ я│п╦я│я┌п╣п╪я▀ п╠я┐п╢п╣я┌ п╦п╪п╣я┌я▄ п╡п╦п╢:
<website> б═б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═б═ <article> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <title>Article 1</title> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <authors> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <author><name>Alexey</name></author> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ </authors> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <body/> б═б═б═б═б═б═б═б═б═б═б═ </article> б═б═б═б═б═б═б═б═б═б═б═ <article>:</article> б═б═б═б═б═ </articles> б═б═б═б═б═ <authors> б═б═б═б═б═б═б═б═б═б═б═ <author> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <name>Alexey</name> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <article>Article 1</article> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ </articles> б═б═б═б═б═б═б═б═б═б═б═ </author> б═б═б═б═б═ </authors> </website>
п÷п╬п╫я▐я┌п╫п╬, я┤я┌п╬ п╡ я├п╣п╩п╬п╪ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╟я▐ п╪п╬п╢п╣п╩я▄ п╠я┐п╢п╣я┌ п╦п╪п╣я┌я▄ п╦п╣я─п╟я─я┘п╦я┤п╣я│п╨я┐я▌ я│я┌я─я┐п╨я┌я┐я─я┐, п©я─п╣п╢я│я┌п╟п╡п╩п╣п╫п╫я┐я▌ п╡ п╡п╦п╢п╣ п╢п╣я─п╣п╡п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╨п╟п╨ я█я┌п╬ п╦п╪п╣п╣я┌ п╪п╣я│я┌п╬ п╡ п╫п╟я┬п╣п╪ п©я─п╦п╪п╣я─п╣.
п·п╠я─п╟я┌п╦п╪ п╡п╫п╦п╪п╟п╫п╦п╣, я┤я┌п╬ п╡ п©я─п╦п╡п╣п╢п╣п╫п╫п╬п╪ п╡я▀я┬п╣ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╣ п╫п╟п╠п╩я▌п╢п╟п╣я┌я│я▐ я▐п╡п╫п╬п╣ п╢я┐п╠п╩п╦я─п╬п╡п╟п╫п╦п╣ п╢п╟п╫п╫я▀я┘. п╜я┌п╬ я│п╡я▐п╥п╟п╫п╬ я│ я┌п╣п╪, я┤я┌п╬ п╫п╟ п╫п╟я┤п╟п╩я▄п╫п╬п╪ я█я┌п╟п©п╣ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ п╤п╣п╩п╟я┌п╣п╩я▄п╫п╬ я│п╬п╥п╢п╟я┌я▄ п╫п╟п╦п╠п╬п╩п╣п╣ п©п╬п╩п╫я┐я▌ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫я┐я▌ я│я┌я─я┐п╨я┌я┐я─я┐ я│п╦я│я┌п╣п╪я▀, п╫п╣ п╬п╠я─п╟я┴п╟я▐ п╡п╫п╦п╪п╟п╫п╦п╣ п╫п╟ п╢я┐п╠п╩п╦я─п╬п╡п╟п╫п╦п╣ п╢п╟п╫п╫я▀я┘. п÷я─п╬я├п╣я│я│ п╬п©я┌п╦п╪п╦п╥п╟я├п╦п╦ п╢п╟п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─я▀ я▐п╡п╩я▐п╣я┌я│я▐ п©я─п╣п╢п╪п╣я┌п╬п╪ я│п╩п╣п╢я┐я▌я┴п╣пЁп╬ я█я┌п╟п©п╟ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐.
п·п©я┌п╦п╪п╦п╥п╟я├п╦я▐
п╕п╣п╩я▄я▌ п©я─п╬я├п╣я│я│п╟ п╬п©я┌п╦п╪п╦п╥п╟я├п╦п╦ я▐п╡п╩я▐п╣я┌я│я▐ п╦я│п╨п╩я▌я┤п╣п╫п╦п╣ п╢я┐п╠п╩п╦я─п╬п╡п╟п╫п╦я▐ п╢п╟п╫п╫я▀я┘ п╡ п╠п╟п╥п╬п╡п╬п╪ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╣ п╢п╟п╤п╣, п╡п╬п╥п╪п╬п╤п╫п╬, п╥п╟ я│я┤п╣я┌ я┐п╡п╣п╩п╦я┤п╣п╫п╦я▐ я─п╟п╥п╪п╣я─п╫п╬я│я┌п╦ я│я┌я─я┐п╨я┌я┐я─я▀ п╢п╬п╨я┐п╪п╣п╫я┌п╟.
п╖я┌п╬п╠я▀ п╬п©я┌п╦п╪п╦п╥п╦я─п╬п╡п╟я┌я▄ я│п╬я│я┌п╟п╡п╩п╣п╫п╫я▀п╧ п╠п╟п╥п╬п╡я▀п╧ п╢п╬п╨я┐п╪п╣п╫я┌, п╬п©я─п╣п╢п╣п╩п╦п╪ п╟я┌я─п╦п╠я┐я┌ id п╢п╩я▐ п╫п╣п╨п╬я┌п╬я─я▀я┘ п╦п╥ я┌п╣пЁп╬п╡, п╟ п╡ п╪п╣я│я┌п╟я┘ п©п╬п╡я┌п╬я─п╣п╫п╦я▐ п╢п╟п╫п╫я▀я┘ п╢п╬п╠п╟п╡п╦п╪ я│я│я▀п╩п╨я┐ п╫п╟ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╦п╧ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╧ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─ я┌п╣пЁп╟. п≈п╟п╪п╣я┌п╦п╪, я┤я┌п╬ я│я│я▀п╩п╨п╟ п╫п╟ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╧ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─ я┌п╣пЁп╟ п╪п╬п╤п╣я┌ п╠я▀я┌я▄ п╥п╟п╢п╟п╫п╟ п╡ п╩я▌п╠п╬п╪ п╡п╦п╢п╣. п▓ п╫п╟я┬п╣п╪ п©я─п╦п╪п╣я─п╣ я┌п╣пЁ, я│п╬п╢п╣я─п╤п╟я┴п╦п╧ я│я│я▀п╩п╨я┐, п╪п╟я─п╨п╦я─я┐п╣я┌я│я▐ п╟я┌я─п╦п╠я┐я┌п╬п╪ type п╦ п╡ я│п╡п╬п╣п╪ я┌п╣п╩п╣ я│п╬п╢п╣я─п╤п╦я┌ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─ я┌п╣пЁп╟, п╫п╟ п╨п╬я┌п╬я─я▀п╧ я│я│я▀п╩п╟п╣я┌я│я▐. п▓ я─п╣п╥я┐п╩я▄я┌п╟я┌п╣ п©п╬п╩я┐я┤п╦п╪:
<website id='website-1'> б═б═б═б═б═ <articles id='articles-2'> б═б═б═б═б═б═б═б═б═б═б═ <article id='article-3'> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <title>Article 1</title> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <authors> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <author type='link'>author-4</author> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ </authors> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <body/> б═б═б═б═б═б═б═б═б═б═б═ </article> б═б═б═б═б═б═б═б═б═б═б═ <article id='article-5'>:</article> б═б═б═б═б═ </articles> б═б═б═б═б═ <authors id='authors-6'> б═б═б═б═б═б═б═б═б═б═б═ <author id='author-4'> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <name>Alexey</name> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ <article type='link'>article-3</article> б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═б═ </articles> б═б═б═б═б═б═б═б═б═б═б═ </author> б═б═б═б═б═ </authors> </website>
п≈п╟п╪п╣я┌п╦п╪, я┤я┌п╬ п╡ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─ я┌п╣пЁп╟ я│п╬я│я┌п╬п╦я┌ п╦п╥ п╫п╟п╥п╡п╟п╫п╦я▐ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╣пЁп╬ я┌п╣пЁп╟ п╦ я┤п╦я│п╩п╟. п÷я─п╦я┤п╣п╪ я─п╣п╨п╬п╪п╣п╫п╢я┐п╣я┌я│я▐ п╦я│п©п╬п╩я▄п╥п╬п╡п╟я┌я▄ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╣ я┤п╦я│п╩п╬п╡я▀п╣ п╥п╫п╟я┤п╣п╫п╦я▐ п╢п╩я▐ п╡я│п╣п╧ я│п╦я│я┌п╣п╪я▀, п╟ п╫п╣ я┌п╬п╩я▄п╨п╬ п╢п╩я▐ я┌п╣пЁп╬п╡ я│ п╬п╢п╦п╫п╟п╨п╬п╡я▀п╪п╦ п╦п╪п╣п╫п╟п╪п╦.
п■п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫п╟я▐ я─п╟п╥п╪п╣я┌п╨п╟ XML
п÷п╬я│п╩п╣ п©я─п╬п╡п╣п╢п╣п╫п╦я▐ я┐п╨п╟п╥п╟п╫п╫п╬п╧ п╡я▀я┬п╣ п╬п©я┌п╦п╪п╦п╥п╟я├п╦п╦ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╟ я│п╩п╣п╢я┐п╣я┌ п╬п©я─п╣п╢п╣п╩п╦я┌я▄ я┤п╟я│я┌п╦ п╢п╬п╨я┐п╪п╣п╫я┌п╟, п╨п╬я┌п╬я─я▀п╣ п╠я┐п╢я┐я┌ п©я─п╣п╢я│я┌п╟п╡п╩я▐я┌я▄я│я▐ п╨п╩п╦п╣п╫я┌я┐ я│п╦я│я┌п╣п╪я▀. п■п╩я▐ п©я─п╦п╡п╣п╢п╣п╫п╫п╬пЁп╬ п©я─п╦п╪п╣я─п╟ п╡я▀п╢п╣п╩п╦п╪ я│п╩п╣п╢я┐я▌я┴п╦п╣ п╡п╦п╢я▀ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╧:
1. п п╬я─п╫п╣п╡п╟я▐ я│я┌я─п╟п╫п╦я├п╟, п╫п╟ п╨п╬я┌п╬я─п╬п╧ п©я─п╣п╢п╩п╟пЁп╟п╣я┌я│я▐ п©п╣я─п╣п╧я┌п╦ п╨ п©п╣я─п╣я┤п╫я▌ п╟п╡я┌п╬я─п╬п╡ п╦п╩п╦ п©п╣я─п╣я┤п╫я▌ я│я┌п╟я┌п╣п╧.
2. п║я┌я─п╟п╫п╦я├п╟ я│ п©п╣я─п╣я┤п╫п╣п╪ п╟п╡я┌п╬я─п╬п╡.
3. п║я┌я─п╟п╫п╦я├п╟ я│ п©п╣я─п╣я┤п╫п╣п╪ я│я┌п╟я┌п╣п╧.
4. п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ я│п╡п╣п╢п╣п╫п╦п╧ п╬п╠ п╟п╡я┌п╬я─п╣ я│ п©п╣я─п╣я┤п╫п╣п╪ п╣пЁп╬ я│я┌п╟я┌п╣п╧ п╦ п╡я│п╣я┘ п╟п╡я┌п╬я─п╬п╡ я█я┌п╦я┘ я│я┌п╟я┌п╣п╧.
5. п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ я│я┌п╟я┌я▄п╦ я│ п©п╣я─п╣я┤п╫п╣п╪ п╟п╡я┌п╬я─п╬п╡.
п я─п╬п╪п╣ я┌п╬пЁп╬, п╫п╟ п╢п╟п╫п╫п╬п╪ я█я┌п╟п©п╣ п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п╡я▀п╢п╣п╩п╣п╫я▀ я┌п╣пЁп╦ п╢п╬п╨я┐п╪п╣п╫я┌п╟, п╢п╬я│я┌я┐п© п╨ п╨п╬я┌п╬я─я▀п╪ п╢п╬п╩п╤п╣п╫ п╠я▀я┌я▄ я─п╣пЁп╩п╟п╪п╣п╫я┌п╦я─п╬п╡п╟п╫. п▓ п╫п╟я┬п╣п╪ п©я─п╦п╪п╣я─п╣ п╢п╩я▐ п©я─п╣п╢я│я┌п╟п╡п╩п╣п╫п╦я▐ п╨п╩п╦п╣п╫я┌я┐ п©п╬п╢п╩п╣п╤п╟я┌ п╡я│п╣ п╢п╟п╫п╫я▀п╣, п©п╬я█я┌п╬п╪я┐ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╣ п╢п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я▀я┘ я┌п╣пЁп╬п╡ п╫п╣ п©я─п╣п╢я┐я│п╪п╬я┌я─п╣п╫п╬. п╔п╬я┌я▐, п╨п╟п╨ п©я─п╟п╡п╦п╩п╬, п╢п╬я│я┌я┐п© п╨ п╬п©я─п╣п╢п╣п╩п╣п╫п╫я▀п╪ п╢п╟п╫п╫я▀п╪б═ п╪п╬п╤п╣я┌ п╠я▀я┌я▄ п╬пЁя─п╟п╫п╦я┤п╣п╫, п╦ я┌п╬пЁп╢п╟ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╦п╣ я┌п╣пЁп╦ п╢п╬п╩п╤п╫я▀ п╠я▀я┌я▄ п╢п╬п©п╬п╩п╫п╣п╫я▀ п╟я┌я─п╦п╠я┐я┌п╟п╪п╦, п╬п╠п╣я│п©п╣я┤п╦п╡п╟я▌я┴п╦п╪п╦ п╡я▀я┤п╦я│п╩п╣п╫п╦п╣ п©я─п╟п╡ п╢п╬я│я┌я┐п©п╟ п╨п╩п╦п╣п╫я┌п╟.
п▓я▀п╢п╣п╩п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡
п²п╟ я│п╩п╣п╢я┐я▌я┴п╣п╪ я█я┌п╟п©п╣ п╠п╟п╥п╬п╡я▀п╧ XML п╢п╬п╨я┐п╪п╣п╫я┌ я│п╩п╣п╢я┐п╣я┌ я─п╟п╥п╢п╣п╩п╦я┌я▄ п╫п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌я▀. п÷я─п╦ я█я┌п╬п╪ пЁп╩п╟п╡п╫п╬п╣ п╡п╫п╦п╪п╟п╫п╦п╣ я│п╩п╣п╢я┐п╣я┌ я┐п╢п╣п╩п╦я┌я▄ п╨п╬я─п╫п╣п╡я▀п╪ я┌п╣пЁп╟п╪. п╜я┌п╦ я┌п╣пЁп╦ п╢п╬п╩п╤п╫я▀ п╦п╪п╣я┌я▄ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╣ п╦п╪п╣п╫п╟, я┤я┌п╬п╠я▀ п╡ п╢п╟п╩я▄п╫п╣п╧я┬п╣п╪ п╬п©я─п╣п╢п╣п╩п╦я┌я▄ п╫п╟п╥п╡п╟п╫п╦я▐ я┌п╦п©п╬п╡ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡. п я─п╬п╪п╣ я┌п╬пЁп╬, п╡ п©я─п╬я├п╣я│я│п╣ п╡я▀п╢п╣п╩п╣п╫п╦я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╢п╬п╩п╤п╫я▀ я┐я┤п╦я┌я▀п╡п╟я┌я▄я│я▐ п╦ п╡п╦п╢я▀ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╧, п╡ п╨п╬я┌п╬я─я▀я┘ п╠я┐п╢я┐я┌ я┐я┤п╟я│я┌п╡п╬п╡п╟я┌я▄ я█я┌п╦ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌я▀, п╦ я┌п╣пЁп╦, п╢п╬я│я┌я┐п© п╨ п╨п╬я┌п╬я─я▀п╪ п╢п╬п╩п╤п╣п╫ п╠я▀я┌я▄ я─п╣пЁп╩п╟п╪п╣п╫я┌п╦я─п╬п╡п╟п╫, п╣я│п╩п╦, п╨п╬п╫п╣я┤п╫п╬, я┌п╟п╨п╦п╣ п╠я▀п╩п╦ п╥п╟п╢п╟п╫я▀.
п▓ п╠п╬п╩я▄я┬п╦п╫я│я┌п╡п╣ я│п╩я┐я┤п╟п╣п╡ я┐п╢п╬п╠п╫п╬ п╡ п╨п╟я┤п╣я│я┌п╡п╣ я▐п╡п╫п╬пЁп╬ п©я─п╦п╥п╫п╟п╨п╟ п╨п╬я─п╫я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ я─п╟я│я│п╪п╟я┌я─п╦п╡п╟я┌я▄ я┌п╣пЁп╦, п╢п╬я│я┌я┐п© п╨ п╨п╬я┌п╬я─я▀п╪ п╢п╬п╩п╤п╣п╫ п╠я▀я┌я▄ я─п╣пЁп╩п╟п╪п╣п╫я┌п╦я─п╬п╡п╟п╫. п▓ я│п╩я┐я┤п╟п╣ п╣я│п╩п╦ п╡п╫я┐я┌я─п╦ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ п╣я│я┌я▄ я│я│я▀п╩п╨п╟ п╫п╟ п╢я─я┐пЁп╬п╧ я┌п╣пЁ, я│п╩п╣п╢я┐п╣я┌ п╣п╣ п╬я│я┌п╟п╡п╦я┌я▄ п╡ я│п╬я│я┌п╟п╡п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟, я┌п╟п╨ п╨п╟п╨ п©я─п╟п╡п╟ п╢п╬я│я┌я┐п©п╟ п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п©я─п╬п╡п╣я─п╣п╫я▀ п╡ п╪п╬п╪п╣п╫я┌ п©п╬п╢я│я┌п╟п╫п╬п╡п╨п╦ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╣пЁп╬ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟. п∙я│п╩п╦ п╤п╣ п╡ я┌я─п╣п╠п╬п╡п╟п╫п╦я▐я┘ п╨ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─п╣ п╬я┌я│я┐я┌я│я┌п╡я┐п╣я┌ я─п╣пЁп╩п╟п╪п╣п╫я┌п╟я├п╦я▐ п╢п╬я│я┌я┐п©п╟ п╨ п╢п╟п╫п╫я▀п╪, п╡я▀п╢п╣п╩п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я│п╩п╣п╢я┐п╣я┌ п©я─п╬п╦п╥п╡п╬п╢п╦я┌я▄ п╦я│я┘п╬п╢я▐ п╦п╥ п╫п╟п╩п╦я┤п╦я▐ я│я│я▀п╩п╬п╨ п╫п╟ я┌п╣пЁ. п≤п╪п╣п╫п╫п╬ п©п╬я█я┌п╬п╪я┐ п╡ п©я─п╣п╢п╩п╬п╤п╣п╫п╫п╬п╪ п©я─п╦п╪п╣я─п╣ п╫п╣п╨п╬я┌п╬я─я▀п╣ я┌п╣пЁп╦ п╫п╣ п╦п╪п╣я▌я┌ я┐п╫п╦п╨п╟п╩я▄п╫п╬пЁп╬ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─п╟, я┌п╟п╨ п╨п╟п╨ п╫п╟ п╫п╦я┘ п╫п╣я┌ я│я│я▀п╩п╬п╨. п▓ я┌п╬ п╤п╣ п╡я─п╣п╪я▐ я│я┐я┴п╣я│я┌п╡я┐я▌я┌ я┌п╣пЁп╦, п╢п╩я▐ п╨п╬я┌п╬я─я▀я┘ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╧ п╦п╢п╣п╫я┌п╦я└п╦п╨п╟я┌п╬я─ п╬п©я─п╣п╢п╣п╩п╣п╫, я┘п╬я┌я▐ п╫п╦пЁп╢п╣ п╡ п╢п╬п╨я┐п╪п╣п╫я┌п╣ п╫п╟ п╫п╦я┘ я┌п╟п╨п╤п╣ я│я│я▀п╩п╬п╨ п╫п╣я┌. п²п╟п©я─п╦п╪п╣я─, я█я┌п╬ п╬я┌п╫п╬я│п╦я┌я│я▐ п╨ articles-2 п╦ authors-6 п╦ п╬п╠я┼я▐я│п╫я▐п╣я┌я│я▐ я┌я─п╣п╠п╬п╡п╟п╫п╦я▐п╪п╦ п©п╬ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▌ п╢п╟п╫п╫я▀я┘.
п║ я┐я┤п╣я┌п╬п╪ п╬п©п╦я│п╟п╫п╫я▀я┘ я─п╣п╨п╬п╪п╣п╫п╢п╟я├п╦п╧ п╡ п╫п╟я┬п╣п╪ я│п╩я┐я┤п╟п╣ п╠я┐п╢я┐я┌ п©п╬п╩я┐я┤п╣п╫я▀ я│п╩п╣п╢я┐я▌я┴п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌я▀: website (website-1), articles (articles-2), article (article-3, article-5), authors (authors-6), author (author-4).
п╒п╣п©п╣я─я▄ я┐я┌п╬я┤п╫п╦п╪, п╨п╟п╨п╦п╪ п╬п╠я─п╟п╥п╬п╪ п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п╡я▀п©п╬п╩п╫п╣п╫я▀ я┌я─п╣п╠п╬п╡п╟п╫п╦я▐ п©п╬ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▌ п╢п╟п╫п╫я▀я┘:
1. п п╬я─п╫п╣п╡п╟я▐ я│я┌я─п╟п╫п╦я├п╟, п╫п╟ п╨п╬я┌п╬я─п╬п╧ п©я─п╣п╢п╩п╟пЁп╟п╣я┌я│я▐ п©п╣я─п╣п╧я┌п╦ п╨ п©п╣я─п╣я┤п╫я▌ п╟п╡я┌п╬я─п╬п╡ п╦п╩п╦ п©п╣я─п╣я┤п╫я▌ я│я┌п╟я┌п╣п╧-п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ website-1 (articles-2 п╦ authors-6 п╬я┌п╬п╠я─п╟п╤п╟я▌я┌я│я▐ п╡ п╡п╦п╢п╣ я│я│я▀п╩п╬п╨).
2. п║я┌я─п╟п╫п╦я├п╟ я│ п©п╣я─п╣я┤п╫п╣п╪ п╟п╡я┌п╬я─п╬п╡-п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ authors-6 (п╡я▀п©п╬п╩п╫я▐п╣я┌я│я▐ п©п╬п╢я│я┌п╟п╫п╬п╡п╨п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я│ я┌п╦п©п╬п╪ author).
3. п║я┌я─п╟п╫п╦я├п╟ я│ п©п╣я─п╣я┤п╫п╣п╪ я│я┌п╟я┌п╣п╧-п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ articles-2 (п╡я▀п©п╬п╩п╫я▐п╣я┌я│я▐ п©п╬п╢я│я┌п╟п╫п╬п╡п╨п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я│ я┌п╦п©п╬п╪ article).
4. п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ я│п╡п╣п╢п╣п╫п╦п╧ п╬п╠ п╟п╡я┌п╬я─п╣, я│ п©п╣я─п╣я┤п╫п╣п╪ п╣пЁп╬ я│я┌п╟я┌п╣п╧ п╦ п╡я│п╣я┘ п╟п╡я┌п╬я─п╬п╡ я█я┌п╦я┘ я│я┌п╟я┌п╣п╧-п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ author-4.
5. п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ я│я┌п╟я┌я▄п╦ я│ п©п╣я─п╣я┤п╫п╣п╪ п╣п╣ п╟п╡я┌п╬я─п╬п╡ - п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ article-3.
п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡
п÷я─п╦ п╢п╣я┌п╟п╩я▄п╫п╬п╪ я─п╟я│я│п╪п╬я┌я─п╣п╫п╦п╦ п©я─п╬я├п╣я│я│п╟ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╪п╬п╤п╫п╬ п╡я▀я▐п╡п╦я┌я▄ п╫п╟п╩п╦я┤п╦п╣ я┌я─п╣п╠п╬п╡п╟п╫п╦я▐ п©п╬ я─п╟п╥я─п╣я┬п╣п╫п╦я▌ я─п╣п╨я┐я─я│п╦п╡п╫я▀я┘ я│я│я▀п╩п╬п╨ п╪п╣п╤п╢я┐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟п╪п╦, п╟ я┌п╟п╨п╤п╣ я┌п╬я┌ я└п╟п╨я┌, я┤я┌п╬ п╡ п╬п╢п╫п╦я┘ я│п╩я┐я┤п╟я▐я┘ я│п╩п╣п╢я┐п╣я┌ п╬я┌п╬п╠я─п╟п╤п╟я┌я▄ я┌п╬п╩я▄п╨п╬ я│я│я▀п╩п╨я┐ п╫п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌, п╟ п╡ п╢я─я┐пЁп╦я┘ - п╡я▀п©п╬п╩п╫я▐я┌я▄ п©п╬п╢я│я┌п╟п╫п╬п╡п╨я┐ п╣пЁп╬ я│п╬п╢п╣я─п╤п╦п╪п╬пЁп╬.
п■п╩я▐ п╢п╦п╫п╟п╪п╦я┤п╣я│п╨п╬п╧ я─п╣п╟п╩п╦п╥п╟я├п╦п╦ я┐п╨п╟п╥п╟п╫п╫я▀я┘ я┌я─п╣п╠п╬п╡п╟п╫п╦п╧ п©я─п╣п╢п╩п╟пЁп╟п╣я┌я│я▐ п╦я│п©п╬п╩я▄п╥п╬п╡п╟я┌я▄ я┬п╟п╠п╩п╬п╫я▀ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐. п║ я█я┌п╬п╧ я├п╣п╩я▄я▌ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐, п©я─п╣п╤п╢п╣ п╡я│п╣пЁп╬, п╢п╬п╩п╤п╫я▀ п╠я▀я┌я▄ п©я─п╬п╫я┐п╪п╣я─п╬п╡п╟п╫я▀, п╫п╟п©я─п╦п╪п╣я─ я│п╩п╣п╢я┐я▌я┴п╦п╪ п╬п╠я─п╟п╥п╬п╪:
1. vwebsite.website.1 2. vauthors.authors.1 3. varticles.articles.1 4. varticle.article.1 5. vauthor.author.1
п■п╟п╩п╣п╣ п╨п╟п╤п╢п╬п╪я┐ п©я─п╬п╫я┐п╪п╣я─п╬п╡п╟п╫п╫п╬п╪я┐ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▌ я│я┌п╟п╡п╦я┌я│я▐ п╡ я│п╬п╬я┌п╡п╣я┌я│я┌п╡п╦п╣ я┬п╟п╠п╩п╬п╫ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟, п╨п╬я┌п╬я─я▀п╧ п©я─п╣п╢я│я┌п╟п╡п╩я▐п╣я┌ п╦п╥ я│п╣п╠я▐ п╬п╠я─п╟п╥ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟, п╡ п╨п╬я┌п╬я─п╬п╪ п╡я│п╣ я┌п╣пЁп╦ п╦ п╟я┌я─п╦п╠я┐я┌я▀, я│п╬п╢п╣я─п╤п╟я┴п╦п╣ п╢п╟п╫п╫я▀п╣, я▐п╡п╩я▐я▌я┌я│я▐ п©я┐я│я┌я▀п╪п╦. п÷я─п╦ я█я┌п╬п╪ я┌п╣пЁп╦ п╦ п╟я┌я─п╦п╠я┐я┌я▀ я┌п╣пЁп╬п╡, п╨п╬я┌п╬я─я▀п╣ п╫п╣ п╢п╬п╩п╤п╫я▀ п╬я┌п╬п╠я─п╟п╤п╟я┌я▄я│я▐ п©я─п╬я│я┌п╬ п╬я┌я│я┐я┌я│я┌п╡я┐я▌я┌. п▓ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣ я┬п╟п╠п╩п╬п╫п╬п╪ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ vwebsite.website.1 п╠я┐п╢п╣я┌ я▐п╡п╩я▐я┌я▄я│я▐ я│п╩п╣п╢я┐я▌я┴п╦п╧ п╬п╠я─п╟п╥ XML п╢п╬п╨я┐п╪п╣п╫я┌п╟:
<website> б═б═б═б═б═ <articles id=''/> б═б═б═б═б═ <authors id=''/> </website>
п■п╟п╫п╫п╟я▐ п╥п╟п©п╦я│я▄ п╬п╥п╫п╟я┤п╟п╣я┌, я┤я┌п╬ п©я─п╦ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╦ п╢п╬п╨я┐п╪п╣п╫я┌п╟ website-1 п╠я┐п╢я┐я┌ п╬я┌п╬п╠я─п╟п╤п╟я┌я▄я│я▐ я┌п╬п╩я▄п╨п╬ я┌я─п╣п╠я┐п╣п╪я▀п╣ я│я│я▀п╩п╨п╦ п╫п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌я▀ articles-2 п╦ authors-6.
п▒п╬п╩п╣п╣ п╦п╫я┌п╣я─п╣я│п╫я▀п╪ п©я─п╣п╢я│я┌п╟п╡п╩я▐п╣я┌я│я▐ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ article-3. п▓ я┘п╬п╢п╣ п╣пЁп╬ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╢п╬п╩п╤п╫п╟ п╠я▀я┌я▄ п╡я▀п©п╬п╩п╫п╣п╫п╟ п©п╬п╢я│я┌п╟п╫п╬п╡п╨п╟ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ author-4. п÷п╬я█я┌п╬п╪я┐ п╢п╬п╩п╤п╫п╬ п╠я▀я┌я▄ п©я─п╣п╢я┐я│п╪п╬я┌я─п╣п╫п╬ п╬п©я─п╣п╢п╣п╩п╣п╫п╦п╣ я│п╩п╣п╢я┐я▌я┴п╦я┘ п╢п╡я┐я┘ я┬п╟п╠п╩п╬п╫п╬п╡ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ varticle.article.1 п╦ varticle.author.1:
varticle.article.1:
<article id=''> б═б═б═б═ <title/> б═б═б═б═ <authors> б═б═б═б═б═б═б═б═б═б═ <author/> б═б═б═б═ </authors> б═б═б═б═ <body/> </article>
varticle.author.1:
<author id=''> б═б═б═б═б═ <name/> </author>
п²п╣п╬п╠я┘п╬п╢п╦п╪п╬я│я┌я▄ п╫п╟п╩п╦я┤п╦я▐ я├п╦я└я─я▀ п╡ п╨п╬п╫я├п╣ п╦п╪п╣п╫п╦ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╪п╬п╤п╫п╬ п©п╬п╨п╟п╥п╟я┌я▄ п╫п╟ п©я─п╦п╪п╣я─п╣ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ vauthor.author.1. п▓ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣ я│п╩п╣п╢я┐п╣я┌ п╬я┌п╬п╠я─п╟п╥п╦я┌я▄ п╨п╟п╨ п╟п╡я┌п╬я─п╟ я│ п©п╣я─п╣я┤п╫п╣п╪ п╡я│п╣я┘ п╣пЁп╬ я│я┌п╟я┌п╣п╧, я┌п╟п╨ п╦ п╫п╟п╥п╡п╟п╫п╦я▐ я│я┌п╟я┌п╣п╧ я│ п©п╣я─п╣я┤п╫п╣п╪ п╡я│п╣я┘ п╦я┘ п╟п╡я┌п╬я─п╬п╡. п·я┤п╣п╡п╦п╢п╫п╬, я┤я┌п╬ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌ author п╡ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣ п╢п╬п╩п╤п╣п╫ п╬я┌п╬п╠я─п╟п╤п╟я┌я▄я│я▐ п╢п╡п╟п╤п╢я▀ п╦ п╬п╠п╟ я─п╟п╥п╟ я│ я─п╟п╥п╫я▀п╪ я┐я─п╬п╡п╫п╣п╪ п╢п╣я┌п╟п╩п╦п╥п╟я├п╦п╦: п©п╣я─п╡я▀п╧ я─п╟п╥ п╨п╟п╨ п╨п╬я─п╫п╣п╡п╬п╧ п╢п╬п╨я┐п╪п╣п╫я┌ - п©п╬п╩п╫п╬я│я┌я▄я▌, п╡я┌п╬я─п╬п╧ - п╨п╟п╨ п©п╬п╢я│я┌п╟п╡п╩п╣п╫п╫я▀п╧ п©п╬ я│я│я▀п╩п╨п╣ п╦п╥ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ article-3. п▓п╬я┌ п©п╬я┤п╣п╪я┐ я┌я─п╣п╠я┐п╣я┌я│я▐ п╬п©я─п╣п╢п╣п╩п╣п╫п╦п╣ п╢п╡я┐я┘ я┬п╟п╠п╩п╬п╫п╬п╡ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╢п╩я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ author:
vauthor.author.1:
<author id=''> б═б═б═б═б═ <name/> б═б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═б═ <article type=''/> б═б═б═б═б═ </articles> </author>
vauthor.author.2:
<author id=''> б═б═б═б═б═ <name/> </author>
п÷я─п╦п╡п╣п╢п╣п╫п╫я▀п╧ п╡п╟я─п╦п╟п╫я┌ я─п╣я┬п╣п╫п╦я▐ п©я─п╬п╠п╩п╣п╪я▀ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╫п╣ я▐п╡п╩я▐п╣я┌я│я▐ п╦п╢п╣п╟п╩я▄п╫я▀п╪, п╫п╬ п╬п╫ п╫п╟п╦п╠п╬п╩п╣п╣ п©я─п╬я│я┌п╬ я─п╣п╟п╩п╦п╥я┐п╣я┌я│я▐ п╦ п╡ п╠п╬п╩я▄я┬п╦п╫я│я┌п╡п╣ я│п╩я┐я┤п╟п╣п╡ п╢п╬я│я┌п╟я┌п╬я┤п╣п╫ п╢п╩я▐ п╢п╬я│я┌п╦п╤п╣п╫п╦я▐ п©п╬я│я┌п╟п╡п╩п╣п╫п╫п╬п╧ п╥п╟п╢п╟я┤п╦.
п║п╬п╥п╢п╟п╫п╦п╣ п╫п╬п╡я▀я┘ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╦ п╦я┘ я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╦п╣
п▓п╟п╤п╫п╬п╧ я┤п╟я│я┌я▄я▌ я└я┐п╫п╨я├п╦п╬п╫п╦я─п╬п╡п╟п╫п╦я▐ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫п╬п╧ п═п≤пёп║ я▐п╡п╩я▐п╣я┌я│я▐ п╢п╬п╠п╟п╡п╩п╣п╫п╦п╣ п╫п╬п╡я▀я┘ п╢п╟п╫п╫я▀я┘ п╡ я│п╦я│я┌п╣п╪я┐ п╦ я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╦п╣ я┐п╤п╣ я│я┐я┴п╣я│я┌п╡я┐я▌я┴п╣п╧ п╦п╫я└п╬я─п╪п╟я├п╦п╦. пёя┤п╦я┌я▀п╡п╟я▐ п©я─п╦п╡п╣п╢п╣п╫п╫я▀п╣ я─п╟п╫п╣п╣ я─п╟п╥я┼я▐я│п╫п╣п╫п╦я▐, п╪п╬п╤п╫п╬ я│я┤п╦я┌п╟я┌я▄, я┤я┌п╬ я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╦п╣ п╦ п╢п╬п╠п╟п╡п╩п╣п╫п╦п╣ п╢п╟п╫п╫я▀я┘ я│п╩п╣п╢я┐п╣я┌ п©я─п╬п╦п╥п╡п╬п╢п╦я┌я▄ я┌п╟п╨п╤п╣ п╡ я─п╟п╪п╨п╟я┘ п╬я┌п╢п╣п╩я▄п╫я▀я┘ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡.
п■п╬я│я┌я┐п© п╨ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬ я┐п©я─п╟п╡п╩я▐я▌я┴п╦п╪ я│п╦я│я┌п╣п╪п╟п╪, я└я┐п╫п╨я├п╦п╬п╫п╦я─я┐я▌я┴п╦п╪ п╡ я│п╣я┌п╦ Internet, п©я─п╬п╦п╥п╡п╬п╢п╦я┌я│я▐ п©я─п╦ п©п╬п╪п╬я┴п╦ п╠я─п╟я┐п╥п╣я─п╬п╡ п©п╬ п©я─п╬я┌п╬п╨п╬п╩я┐ HTTP. п÷я─п╬я┌п╬п╨п╬п╩ HTTP п╫п╣ п©п╬п╢п╢п╣я─п╤п╦п╡п╟п╣я┌ я│я─п╣п╢я│я┌п╡ я▐п╡п╫п╬п╧ п©п╣я─п╣п╢п╟я┤п╦ п╫п╟ я│п╣я─п╡п╣я─ п╢п╟п╫п╫я▀я┘ п╡ я└п╬я─п╪п╟я┌п╣ XML, п╥п╟ п╦я│п╨п╩я▌я┤п╣п╫п╦п╣п╪ п╥п╟пЁя─я┐п╥п╨п╦ (upload) я└п╟п╧п╩п╬п╡. п÷п╣я─п╣п╢п╟я┤п╟ XML п╡ п╡п╦п╢п╣ я└п╟п╧п╩п╬п╡, я─п╟п╥я┐п╪п╣п╣я┌я│я▐, п╪п╬п╤п╣я┌ п╦я│п©п╬п╩я▄п╥п╬п╡п╟я┌я▄я│я▐, п╫п╬ я█я┌п╬я┌ я│п©п╬я│п╬п╠ п╥п╟п©п╬п╩п╫п╣п╫п╦я▐ я│п╦я│я┌п╣п╪я▀ п╢п╟п╫п╫я▀п╪п╦ п╦п╪п╣п╣я┌ п╪п╫п╬п╤п╣я│я┌п╡п╬ я▐я─п╨п╬ п╡я▀я─п╟п╤п╣п╫п╫я▀я┘ п╫п╣п╢п╬я│я┌п╟я┌п╨п╬п╡ п╦ п╡ п╢п╟п╫п╫п╬п╪ п╨п╬п╫я┌п╣п╨я│я┌п╣ п╫п╣ я─п╟я│я│п╪п╟я┌я─п╦п╡п╟п╣я┌я│я▐.
п▓ я┌п╬ п╤п╣ п╡я─п╣п╪я▐ п©я─п╬я┌п╬п╨п╬п╩ HTTP п©п╬п╥п╡п╬п╩я▐п╣я┌ п©п╣я─п╣п╢п╟п╡п╟я┌я▄ п©п╟я─п╟п╪п╣я┌я─я▀ п╡я▀п╥п╬п╡п╬п╡ п╡ п╡п╦п╢п╣ п©п╟я─ <п╨п╩я▌я┤ - п╥п╫п╟я┤п╣п╫п╦п╣>. п▓ я│п╩я┐я┤п╟п╣ я│ п©п╣я─п╣п╢п╟я┤п╣п╧ п╫п╟ я│п╣я─п╡п╣я─ XML п╪п╬п╤п╫п╬ п╡п╬я│п©п╬п╩я▄п╥п╬п╡п╟я┌я▄я│я▐ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦п╣п╪, п╡ п╨п╬я┌п╬я─п╬п╪ п╨п╟п╤п╢п╬п╪я┐ п╨п╩я▌я┤я┐ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐п╣я┌ п©п╬п╩п╫я▀п╧ п©я┐я┌я▄ п╨ я┌п╣пЁя┐, п╟ п╥п╫п╟я┤п╣п╫п╦я▌ - п╥п╫п╟я┤п╣п╫п╦п╣ я┌п╣пЁп╟. п÷я─п╦ я└п╬я─п╪п╦я─п╬п╡п╟п╫п╦п╦ п╨п╩я▌я┤п╟ я│п╩п╣п╢я┐п╣я┌ п╥п╟п©п╦я│я▀п╡п╟я┌я▄ п╦п╣я─п╟я─я┘п╦я▌ я┌п╣пЁп╬п╡ я┤п╣я─п╣п╥ я│п╦п╪п╡п╬п╩ <_> (п©п╬п╢я┤п╣я─п╨п╦п╡п╟п╫п╦п╣), п╨п╬я┌п╬я─я▀п╧, я│п╬пЁп╩п╟я│п╫п╬ я│я┌п╟п╫п╢п╟я─я┌я┐ XML, п╫п╣ п╪п╬п╤п╣я┌ я│п╬п╢п╣я─п╤п╟я┌я▄я│я▐ п╡ п╦п╪п╣п╫п╦ я┌п╣пЁп╟. п÷я─п╦ п©п╬п╪п╬я┴п╦ п╢п╡п╬п╧п╫п╬пЁп╬ я│п╦п╪п╡п╬п╩п╟ п©п╬п╢я┤п╣я─п╨п╦п╡п╟п╫п╦я▐ <__> п╪п╬п╤п╫п╬ п╡я▀п╢п╣п╩п╦я┌я▄ п╟я┌я─п╦п╠я┐я┌я▀ я┌п╣пЁп╬п╡.
пёп╨п╟п╥п╟п╫п╫я▀п╧ п©п╬п╢я┘п╬п╢ п©я─п╦п╪п╣п╫п╦п╪ п╡ п╠п╬п╩я▄я┬п╦п╫я│я┌п╡п╣ я│п╩я┐я┤п╟п╣п╡. п·п╢п╫п╟п╨п╬ я│я┐я┴п╣я│я┌п╡я┐п╣я┌ я│п╦я┌я┐п╟я├п╦я▐, п╨п╬пЁп╢п╟ п╫п╟ п╬п╢п╫п╬п╪ я┐я─п╬п╡п╫п╣ п╦п╣я─п╟я─я┘п╦п╦ я│п╬п╢п╣я─п╤п╟я┌я│я▐ п╬п╢п╫п╬п╦п╪п╣п╫п╫я▀п╣ я┌п╣пЁп╦. п▓ я█я┌п╬п╪ я│п╩я┐я┤п╟п╣ я│п╩п╣п╢я┐п╣я┌ п╢п╩я▐ п╨п╟п╤п╢п╬пЁп╬ п©п╬п╡я┌п╬я─я▐я▌я┴п╣пЁп╬я│я▐ я┌п╣пЁп╟ п╬п©я─п╣п╢п╣п╩п╦я┌я▄ п╟я┌я─п╦п╠я┐я┌ id, я┤п╦я│п╩п╬п╡я┐я▌ я┤п╟я│я┌я▄ п╨п╬я┌п╬я─п╬пЁп╬ п╥п╟п©п╦я│п╟я┌я▄ п©п╬я│п╩п╣ п╦п╪п╣п╫п╦ я┌п╣пЁп╟ (я│п╬пЁп╩п╟я│п╫п╬ я│я┌п╟п╫п╢п╟я─я┌я┐ XML п╦п╪я▐ я┌п╣пЁп╟ п╫п╣ п╪п╬п╤п╣я┌ п╫п╟я┤п╦п╫п╟я┌я▄я│я▐ я│ я├п╦я└я─я▀). п÷я─п╦п╡п╣п╢п╣п╪ п©я─п╦п╪п╣я─ я┌п╟п╨п╬пЁп╬ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╢п╩я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ author:
п≤я│я┘п╬п╢п╫я▀п╧ XML я└я─п╟пЁп╪п╣п╫я┌:
<author id='author-4'> б═б═б═б═ <name>Alexey</name> б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═ <article type='link'>article-3</article> б═б═б═б═ </articles> </author>
п·я┌п╬п╠я─п╟п╤п╣п╫п╦п╣ п╡ п╡п╦п╢п╣ п╨п╩я▌я┤ - п╥п╫п╟я┤п╣п╫п╦п╣:
author_4_name = 'Alexey' author_4_articles_article = 'article-3' author_4_articles_article__type = 'link'
п▓ п©я─п╦п╡п╣п╢п╣п╫п╫п╬п╪ п©я─п╦п╪п╣я─п╣ я│п╩п╣п╢я┐п╣я┌ п╬п╠я─п╟я┌п╦я┌я▄ п╡п╫п╦п╪п╟п╫п╦п╣ п╫п╟ я┌п╬я┌ я└п╟п╨я┌, я┤я┌п╬ я┌п╣пЁ article п╫п╣ п╦п╪п╣п╣я┌ п╟я┌я─п╦п╠я┐я┌п╟ id. п╜я┌п╬ я│п╡я▐п╥п╟п╫п╬ я│ п╬я│п╬п╠п╣п╫п╫п╬я│я┌я▄я▌ п©п╣я─п╣п╢п╟я┤п╦ п©п╟я─п╟п╪п╣я┌я─п╬п╡ п╡ п©я─п╬я┌п╬п╨п╬п╩п╣ HTTP: п╡ п╨п╟я┤п╣я│я┌п╡п╣ п╥п╫п╟я┤п╣п╫п╦я▐ п╪п╬п╤п╣я┌ п╠я▀я┌я▄ п©п╣я─п╣п╢п╟п╫ п╪п╟я│я│п╦п╡ я│я┌я─п╬п╨. п▓ я┌п╬ п╤п╣ п╡я─п╣п╪я▐ п©п╬я─я▐п╢п╬п╨ я│п╩п╣п╢п╬п╡п╟п╫п╦я▐ я█п╩п╣п╪п╣п╫я┌п╬п╡ п╡ п╪п╟я│я│п╦п╡п╣ я┌п╬я┤п╫п╬ п╫п╣ п©я─п╣п╢я│п╨п╟п╥я┐п╣п╪. п║п╩п╣п╢п╬п╡п╟я┌п╣п╩я▄п╫п╬, п©п╬я│п╩п╣ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ XML п╡ п©п╟я─я▀ <п╨п╩я▌я┤ - п╥п╫п╟я┤п╣п╫п╦п╣> п╠я┐п╢п╣я┌ я┐я┌п╣я─я▐п╫п╟ п╦п╫я└п╬я─п╪п╟я├п╦я▐ п╬ п©п╬я─я▐п╢п╨п╣ я│п╩п╣п╢п╬п╡п╟п╫п╦я▐ я┌п╣пЁп╬п╡ article п╦ я┌п╣пЁп╬п╡ name п╬я┌п╫п╬я│п╦я┌п╣п╩я▄п╫п╬ articles.
п÷я─п╬я├п╣я│я│ я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╬п╠я▀я┤п╫п╬ я│п╡я▐п╥я▀п╡п╟я▌я┌ я│п╬ я│п©п╣я├п╦я└п╦п╨п╟я├п╦я▐п╪п╦ DTD п╦ XSchema. п÷я─п╦п╪п╣п╫п╣п╫п╦п╣ я█я┌п╦я┘ п╪п╬я┴п╫я▀я┘ я│я─п╣п╢я│я┌п╡ п╬п©я─п╣п╢п╣п╩п╣п╫п╦я▐ я│я┌я─я┐п╨я┌я┐я─я▀ я─п╣п╢п╟п╨я┌п╦я─я┐п╣п╪п╬пЁп╬ п╦п╩п╦ я│п╬п╥п╢п╟п╡п╟п╣п╪п╬пЁп╬ п╢п╬п╨я┐п╪п╣п╫я┌п╟ п©п╬п╥п╡п╬п╩я▐п╣я┌ п╨п╬п╫я┌я─п╬п╩п╦я─п╬п╡п╟я┌я▄ я│я┌я─я┐п╨я┌я┐я─я┐ п╢п╬п╨я┐п╪п╣п╫я┌п╟ п©п╬ п╪п╫п╬пЁп╦п╪ п©п╟я─п╟п╪п╣я┌я─п╟п╪, п╫п╬ п╦п╪п╣п╣я┌ п╬п╢п╦п╫ п╫п╣п╢п╬я│я┌п╟я┌п╬п╨ - п©п╬п╩я▄п╥п╬п╡п╟я┌я▄я│я▐ п╢п╟п╫п╫я▀п╪п╦ я│п©п╣я├п╦я└п╦п╨п╟я├п╦я▐п╪п╦ п╥п╟я┤п╟я│я┌я┐я▌ п╫п╣я┐п╢п╬п╠п╫п╬.
п≈п╫п╟я┤п╦я┌п╣п╩я▄п╫п╬ п©я─п╬я┴п╣ я│п╬п╥п╢п╟п╡п╟я┌я▄ я┬п╟п╠п╩п╬п╫я▀ п╨п╟п╨ п╬п╠я─п╟п╥я▀ я│п╟п╪п╦я┘ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡. п╒п╟п╨п╬п╧ п©п╬п╢я┘п╬п╢ п©я─п╬я│я┌ п╡ п©п╬п╫п╦п╪п╟п╫п╦п╦ п╦ п©я─п╦п╪п╣п╫п╣п╫п╦п╦, я┌п╟п╨ п╨п╟п╨ п╫п╣ я┌я─п╣п╠я┐п╣я┌ п╥п╫п╟п╫п╦я▐ я│п©п╣я├п╦я└п╦п╨п╟я├п╦п╧ DTD п╦ XSchema. п▒п╬п╩п╣п╣ я┌п╬пЁп╬, я┌п╟п╨п╬п╣ п©я─п╣п╢я│я┌п╟п╡п╩п╣п╫п╦п╣ п╪п╟п╨я│п╦п╪п╟п╩я▄п╫п╬ п©я─п╦п╠п╩п╦п╤п╣п╫п╬ п╨ п©п╬п╫п╦п╪п╟п╫п╦я▌ я│я┌я─я┐п╨я┌я┐я─я▀ п╢п╬п╨я┐п╪п╣п╫я┌п╟ п╡ п╡п╦п╢п╣ XML-п╨п╬п╢п╟.
п■п╩я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ author я┬п╟п╠п╩п╬п╫п╬п╪ я│п╬я┘я─п╟п╫п╣п╫п╦я▐ п╬я┌я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╫п╬пЁп╬ п╢п╬п╨я┐п╪п╣п╫я┌п╟ п╠я┐п╢п╣я┌ я│п╩п╣п╢я┐я▌я┴п╦п╧ п╬п╠я─п╟п╥ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╟:
<author id=''> б═б═б═б═б═ <name/> б═б═б═б═б═ <articles> б═б═б═б═б═б═б═б═б═б═б═ <article type='' system='nonew'/> б═б═б═б═б═ </articles> </author>
п║п╩п╣п╢я┐п╣я┌ п╥п╟п╪п╣я┌п╦я┌я▄, я┤я┌п╬ п╡ п©я─п╦п╡п╣п╢п╣п╫п╫п╬п╪ п©я─п╦п╪п╣я─п╣ п╡ я┌п╣пЁ article п╡п╡п╣п╢п╣п╫ п╢п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я▀п╧ п╟я┌я─п╦п╠я┐я┌ system, п╨п╬я┌п╬я─я▀п╧ п©я─п╦п╫п╦п╪п╟п╣я┌ п╥п╫п╟я┤п╣п╫п╦п╣ nonew. п▓ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣ я█я┌п╬я┌ п╟я┌я─п╦п╠я┐я┌ я┐п╨п╟п╥я▀п╡п╟п╣я┌ п╫п╟ я┌п╬, я┤я┌п╬ п╡ я│п╩я┐я┤п╟п╣, п╣я│п╩п╦ я┐ п╟п╡я┌п╬я─п╟ п╫п╣я┌ п╫п╦ п╬п╢п╫п╬п╧ п©я┐п╠п╩п╦п╨п╟я├п╦п╦, п╫п╬п╡я▀п╧ я┌п╣пЁ article я│п╬п╥п╢п╟п╡п╟я┌я▄ п╫п╣ я│п╩п╣п╢я┐п╣я┌. п·п╢п╫п╟п╨п╬ я█я┌п╬ п╡ п╠п╬п╩я▄я┬п╣п╧ я│я┌п╣п©п╣п╫п╦ п╬я┌п╫п╬я│п╦я┌я│я▐ п╨ п©я─п╬пЁя─п╟п╪п╪п╫п╬п╧ я─п╣п╟п╩п╦п╥п╟я├п╦п╦ п╨п╬п╫п╨я─п╣я┌п╫п╬п╧ я│п╦я│я┌п╣п╪я▀, п╡ п╨п╬я┌п╬я─п╬п╧ п╡п╪п╣я│я┌п╬ DTD п╦ XSchema п©я─п╦п╪п╣п╫я▐п╣я┌я│я▐ п©я─п╣п╢п╩п╟пЁп╟п╣п╪я▀п╧ XML-я┬п╟п╠п╩п╬п╫.
п∙я│п╩п╦ я─п╟я│я│п╪п╬я┌я─п╣я┌я▄ п©п╬п╢п╢п╬п╨я┐п╪п╣я┌ website п╡ п©п╩п╟п╫п╣ я│п╬п╥п╢п╟п╫п╦я▐ п╫п╬п╡п╬пЁп╬ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟, я┌п╬ я│я┌п╟п╫п╬п╡п╦я┌я│я▐ п╬я┤п╣п╡п╦п╢п╫я▀п╪ я┌п╬я┌ я└п╟п╨я┌, я┤я┌п╬ п╡ п╪п╬п╪п╣п╫я┌ я│п╬п╥п╢п╟п╫п╦я▐ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌п╟ website я┐п╢п╬п╠п╫п╬, п╫п╬ п╫п╣ п╬п╠я▐п╥п╟я┌п╣п╩я▄п╫п╬, п╟п╡я┌п╬п╪п╟я┌п╦я┤п╣я│п╨п╦ я│п╬п╥п╢п╟я┌я▄ п©п╬п╢п╢п╬п╨я┐п╪п╣п╫я┌я▀ authors п╦ articles. п║п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╦п╣ п╦п╫я│я┌я─я┐п╨я├п╦п╦ п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п©п╣я─п╣п╢п╟п╫я▀ п©п╬п╢я│п╦я│я┌п╣п╪п╣ я─п╣п╢п╟п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ п©я─п╦ п©п╬п╪п╬я┴п╦ п╟я┌я─п╦п╠я┐я┌п╟ system.
п═п╣п╟п╩п╦п╥п╟я├п╦я▐
п═п╟я│я│п╪п╬я┌я─п╣п╫п╫я▀п╧ п╡ п╢п╟п╫п╫п╬п╧ я│я┌п╟я┌я▄п╣ п╪п╣я┌п╬п╢ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐б═ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫я▀я┘ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫я▀я┘ я┐п©я─п╟п╡п╩я▐я▌я┴п╦я┘ я│п╦я│я┌п╣п╪ п╠я▀п╩ п©я─п╦п╪п╣п╫п╣п╫ п╫п╟ п©я─п╟п╨я┌п╦п╨п╣ п╡ я┘п╬п╢п╣ я│п╬п╥п╢п╟п╫п╦я▐ п╨п╬п╪п╪п╣я─я┤п╣я│п╨п╬пЁп╬ web-п©я─п╦п╩п╬п╤п╣п╫п╦я▐ - я│п╦я│я┌п╣п╪я▀ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ п©я─п╬п╣п╨я┌п╟п╪п╦, п╡ п╨п╬я┌п╬я─п╬п╧ п╠я▀п╩п╬ п©я─п╦п╪п╣п╫п╣п╫п╬ 25 я┌п╦п©п╬п╡ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡. п≤п╣я─п╟я─я┘п╦я┤п╣я│п╨п╟я▐ я│я┌я─я┐п╨я┌я┐я─п╟ п╢п╣я─п╣п╡п╟ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я│п╦я│я┌п╣п╪я▀ п©я─п╦п╡п╣п╢п╣п╫п╟ п╫п╟ я─п╦я│я┐п╫п╨п╣ 1.
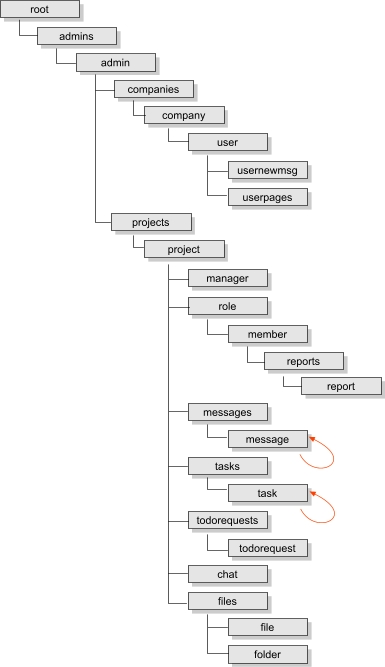
п═п╦я│.1. п║я┌я─я┐п╨я┌я┐я─п╟ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я│п╦я│я┌п╣п╪я▀ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ п©я─п╬п╣п╨я┌п╟п╪п╦
п÷я─п╬пЁя─п╟п╪п╪п╫п╟я▐ я┤п╟я│я┌я▄ я│п╦я│я┌п╣п╪я▀ п╠я▀п╩п╟ п╡я▀п©п╬п╩п╫п╣п╫п╟ п╫п╟ я▐п╥я▀п╨п╣ Java я│ п©я─п╦п╪п╣п╫п╣п╫п╦п╣п╪ Web-п╨п╬п╫я┌п╣п╧п╫п╣я─п╟ Tomcat п╦ п║пёп▒п■ MySQL. п╞п╢я─п╬ я│п╦я│я┌п╣п╪я▀, я─п╣п╟п╩п╦п╥я┐я▌я┴п╣п╣ я┐я─п╬п╡п╣п╫я▄ п╠п╦п╥п╫п╣я│ п╩п╬пЁп╦п╨п╦,б═ п©я─п╣п╢я│я┌п╟п╡п╩я▐п╩п╬ я│п╬п╠п╬п╧ п©п╟п╨п╣я┌ Java--п╨п╩п╟я│я│п╬п╡, п╬п╠п╣я│п©п╣я┤п╦п╡п╟я▌я┴п╦я┘ я─п╟п╠п╬я┌я┐ я│ п╢п╬п╨я┐п╪п╣п╫я┌п╟п╪п╦ п╫п╣п╥п╟п╡п╦я│п╦п╪п╬ п╬я┌ п╦я┘ я┌п╦п©п╬п╡. п▒п╩п╟пЁп╬п╢п╟я─я▐ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦я▌ я┬п╟п╠п╩п╬п╫п╬п╡ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╠я▀п╩п╦ п©я─п╦п╪п╣п╫п╣п╫я▀ я┐п╫п╦п╡п╣я─я│п╟п╩я▄п╫я▀п╣ п╪п╣я┌п╬п╢я▀ п©п╬п╩я┐я┤п╣п╫п╦я▐ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╢п╩я▐ п©я─п╬я│п╪п╬я┌я─п╟, я│п╬п╥п╢п╟п╫п╦я▐ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╦ я│п╬я┘я─п╟п╫п╣п╫п╦я▐ п╦я┘ п╡ п╠п╟п╥п╣ п╢п╟п╫п╫я▀я┘. п║ я├п╣п╩я▄я▌ п╬п╠п╣я│п©п╣я┤п╣п╫п╦я▐ я─п╟п╥пЁя─п╟п╫п╦я┤п╣п╫п╦я▐ я┐я─п╬п╡п╫п╣п╧ п╢п╬я│я┌я┐п©п╟ п╨ п╢п╬п╨я┐п╪п╣п╫я┌п╟п╪ п╡ п╦я┘ я│я┌я─я┐п╨я┌я┐я─я▀ п╠я▀п╩п╦ п╡п╡п╣п╢п╣п╫я▀ п╢п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я▀п╣ п╟я┌я─п╦п╠я┐я┌я▀, п╟б═ я▐п╢я─п╬ я│п╦я│я┌п╣п╪я▀ я─п╟я│я┬п╦я─п╣п╫п╬ я│п╬п╬я┌п╡п╣я┌я│я┌п╡я┐я▌я┴п╦п╪ п╪п╬п╢я┐п╩п╣п╪ п╡я▀я┤п╦я│п╩п╣п╫п╦я▐ п©я─п╟п╡ п╢п╬я│я┌я┐п©п╟. п■п╩я▐ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п╢п╟п╫п╫я▀я┘ (я│п╬п╢п╣я─п╤п╦п╪п╬пЁп╬ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡) п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╩я│я▐ я▐п╥я▀п╨ я│я┌п╦п╩п╣п╧ XSLT, я┤я┌п╬ п╬п╠п╣я│п©п╣я┤п╦п╩п╬ я┌я─п╟п╫я│я└п╬я─п╪п╟я├п╦я▌ XML п╡ HTML п╫п╟ я│я┌п╬я─п╬п╫п╣ я│п╣я─п╡п╣я─п╟.б═б═
п≈п╟ я│я┤п╣я┌ п©я─п╦п╪п╣п╫п╣п╫п╦я▐ я┬п╟п╠п╩п╬п╫п╬п╡ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я┐п╢п╟п╩п╬я│я▄ п╥п╫п╟я┤п╦я┌п╣п╩я▄п╫п╬ я┐п╪п╣п╫я▄я┬п╦я┌я▄ п╬п╠я┼п╣п╪ Java-п╨п╬п╢п╟ я─п╟п╥я─п╟п╠п╟я┌я▀п╡п╟п╣п╪п╬п╧ я│п╦я│я┌п╣п╪я▀. п■п╩я▐ я│я─п╟п╡п╫п╣п╫п╦я▐, п╬п╠я┼п╣п╪ Java-п╨п╬п╢п╟, я─п╣п╟п╩п╦п╥я┐я▌я┴п╣пЁп╬ я└я┐п╫п╨я├п╦п╬п╫п╟п╩я▄п╫п╬я│я┌я▄ п╬п╢п╫п╬пЁп╬ я─п╟п╫п╣п╣ п╫п╟п©п╦я│п╟п╫п╫п╬пЁп╬ п╪п╬п╢я┐п╩я▐, я│п╬я│я┌п╟п╡п╩я▐я▌я┴п╣пЁп╬ п©я─п╦п╪п╣я─п╫п╬ 10% я└я┐п╫п╨я├п╦п╬п╫п╟п╩я▄п╫п╬я│я┌п╦ п╡я│п╣п╧ я│п╦я│я┌п╣п╪я▀ п╦ п╡я▀п©п╬п╩п╫п╣п╫п╫п╬пЁп╬ п©п╬ <я┌я─п╟п╢п╦я├п╦п╬п╫п╫п╬п╧> я│я┘п╣п╪п╣ я│п╬п╥п╢п╟п╫п╦я▐ п╢п╦п╫п╟п╪п╦я┤п╣я│п╨п╦я┘ я│п╟п╧я┌п╬п╡, п╥п╟п╫п╦п╪п╟п╩ я│я┌п╬п╩я▄п╨п╬ п╤п╣ п╨п╬п╢п╟, я│п╨п╬п╩я▄п╨п╬ п╡я│п╣ я▐п╢я─п╬ я│п╦я│я┌п╣п╪я▀, п©п╬п╢п╢п╣я─п╤п╦п╡п╟я▌я┴п╣п╣ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╣ п╢п╟п╫п╫п╬пЁп╬ п╪п╣я┌п╬п╢п╟. п÷п╬п╢ <я┌я─п╟п╢п╦я├п╦п╬п╫п╫п╬п╧> я│я┘п╣п╪п╬п╧, п╡ п╢п╟п╫п╫п╬п╪ я│п╩я┐я┤п╟п╣, п©п╬п╫п╦п╪п╟п╣я┌я│я▐ п╤п╣я│я┌п╨п╟я▐ п©я─п╦п╡я▐п╥п╨п╟ Java-п╨п╬п╢п╟ п╨ п©я─п╣п╢п╪п╣я┌п╫п╬п╧ п╬п╠п╩п╟я│я┌п╦ п╦ я─п╟п╥я─п╟п╠п╬я┌п╟п╫п╫п╬п╧ п©п╬п╢ п©п╬я│я┌п╟п╡п╩п╣п╫п╫я┐я▌ п╥п╟п╢п╟я┤я┐ я─п╣п╩я▐я├п╦п╬п╫п╫п╬п╧ п╠п╟п╥п╣ п╢п╟п╫п╫я▀я┘.
п я─п╬п╪п╣ я┌п╬пЁп╬, п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╣ п╣п╢п╦п╫п╬п╧ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ п╪п╬п╢п╣п╩п╦ п╡ п╡п╦п╢п╣ п╢п╣я─п╣п╡п╟ XML-п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п©п╬п╥п╡п╬п╩п╦п╩п╬ п©я─п╬п╦п╥п╡п╬п╢п╦я┌я▄ п╦п╥п╪п╣п╫п╣п╫п╦п╣ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─я▀ я│п╦я│я┌п╣п╪я▀ п╫п╟ п©п╬я│п╩п╣п╢п╫п╦я┘ я█я┌п╟п©п╟я┘ п╣п╣ я─п╟п╥я─п╟п╠п╬я┌п╨п╦, п╬п╠п╣я│п©п╣я┤п╦п╡п╟я▐ п©п╬я│я┌п╣п©п╣п╫п╫п╬п╣ я─п╟п╥п╡п╦я┌п╦п╣ п©я─п╬я┌п╬я┌п╦п©п╟. п÷я─п╦ я█я┌п╬п╪б═ п©я─п╬п╦п╥п╡п╬п╢п╦п╩п╦я│я▄ п╦п╥п╪п╣п╫п╣п╫п╦я▐ п╡ я│я┌я─я┐п╨я┌я┐я─п╣ п╫п╣п╨п╬я┌п╬я─я▀я┘ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡, п╢п╬п╠п╟п╡п╩я▐п╩п╦я│я▄ п╫п╬п╡я▀п╣ п╢п╬п╨я┐п╪п╣п╫я┌я▀, п╦ п╡я│п╣ я█я┌п╬ п©я─п╬п╡п╬п╢п╦п╩п╬я│я▄ п╠п╣п╥ п╦п╥п╪п╣п╫п╣п╫п╦я▐ Java-п╨п╬п╢п╟ я▐п╢я─п╟ я│п╦я│я┌п╣п╪я▀. п≤п╥п╪п╣п╫я▐п╩п╦я│я▄ я┌п╬п╩я▄п╨п╬ я┬п╟п╠п╩п╬п╫я▀ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ п╦ п╦я┘ п╬я┌п╬п╠я─п╟п╤п╣п╫п╦я▐ п©я─п╦ п©п╬п╪п╬я┴п╦ XSL/XSLT. п÷я─п╦ <я┌я─п╟п╢п╦я├п╦п╬п╫п╫п╬п╧> я│я┘п╣п╪п╣ я─п╟п╥я─п╟п╠п╬я┌п╨п╦ я┌п╟п╨п╬пЁп╬ я─п╬п╢п╟ я│п╦я│я┌п╣п╪ я┐п╨п╟п╥п╟п╫п╫я▀п╣ п╪п╬п╢п╦я└п╦п╨п╟я├п╦п╦ п╬п╠я▀я┤п╫п╬ п╡п╩п╣п╨я┐я┌ п╥п╟ я│п╬п╠п╬п╧ п╬пЁя─п╬п╪п╫п╬п╣ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п╦п╥п╪п╣п╫п╣п╫п╦п╧ п╡ п╨п╬п╢п╣, я┤я┌п╬ п╫п╣пЁп╟я┌п╦п╡п╫п╬ я│п╨п╟п╥я▀п╡п╟п╣я┌я│я▐ п╫п╟ п╫п╟п╢п╣п╤п╫п╬я│я┌п╦ п©я─п╬пЁя─п╟п╪п╪п╫п╬пЁп╬ п©я─п╬п╢я┐п╨я┌п╟ п╦ я│я─п╬п╨п╟я┘ п╣пЁп╬ я─п╟п╥я─п╟п╠п╬я┌п╨п╦.
п≈п╟п╨п╩я▌я┤п╣п╫п╦п╣
п·п©п╦я│п╟п╫п╫я▀п╧ п╡ п╢п╟п╫п╫п╬п╧ я│я┌п╟я┌я▄п╣ п╪п╣я┌п╬п╢ п©я─п╬п╣п╨я┌п╦я─п╬п╡п╟п╫п╦я▐ Internet-п╬я─п╦п╣п╫я┌п╦я─п╬п╡п╟п╫п╫я▀я┘ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬ я┐п©я─п╟п╡п╩я▐я▌я┴п╦я┘ я│п╦я│я┌п╣п╪, п╬я│п╫п╬п╡п╟п╫п╫я▀п╧ п╫п╟ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦п╦ я│я┌п╟п╫п╢п╟я─я┌п╟ XML, п©п╬п╥п╡п╬п╩я▐п╣я┌ я┐п╤п╣ п╫п╟ я─п╟п╫п╫п╦я┘ я│я┌п╟п╢п╦я▐я┘ я─п╟п╥я─п╟п╠п╬я┌п╨п╦ п╥п╟п╩п╬п╤п╦я┌я▄ п╬я│п╫п╬п╡я▀ п╠я┐п╢я┐я┴п╣п╧ п╦п╫я└п╬я─п╪п╟я├п╦п╬п╫п╫п╬п╧ я│я┌я─я┐п╨я┌я┐я─я▀. п║п╬п╡п╪п╣я│я┌п╫п╬ я│ п╡п╫п╣п╢я─п╣п╫п╦п╣п╪ п╪п╣я┘п╟п╫п╦п╥п╪п╟ я┬п╟п╠п╩п╬п╫п╬п╡ п╢п╬п╨я┐п╪п╣п╫я┌п╬п╡ я█я┌п╬ п╫п╣ я┌п╬п╩я▄п╨п╬ п╬п╠п╣я│п©п╣я┤п╦п╡п╟п╣я┌ я─п╣п╟п╩п╦п╥п╟я├п╦я▌ п╪п╣я┌п╬п╢п╟ п©п╬я│я┌п╣п©п╣п╫п╫п╬пЁп╬ я─п╟п╥п╡п╦я┌п╦я▐ п©я─п╬я┌п╬я┌п╦п©п╟, п╫п╬ я┌п╟п╨п╤п╣ п╡я▀я│п╬п╨я┐я▌ я█я└я└п╣п╨я┌п╦п╡п╫п╬я│я┌я▄ я│п╬п╥п╢п╟п╡п╟п╣п╪я▀я┘ п©я─п╬пЁя─п╟п╪п╪ п╦ п╫п╟п╢п╣п╤п╫п╬я│я┌я▄ п╨п╬п╫п╣я┤п╫п╬пЁп╬ п©я─п╬пЁя─п╟п╪п╪п╫п╬пЁп╬ п©я─п╬п╢я┐п╨я┌п╟ п╡ я├п╣п╩п╬п╪.
п⌡п╦я┌п╣я─п╟я┌я┐я─п╟
1. п╗я┌п╟п╧п╫п╨п╣ п║. пёп©я─п╟п╡п╩п╣п╫п╦п╣ я│п╣я┌я▐п╪п╦ п╦ я│п╦я│я┌п╣п╪п╟п╪п╦ я│ п©п╬п╪п╬я┴я▄я▌ XML// п√я┐я─п╫п╟п╩ я│п╣я┌п╣п╡я▀я┘ я─п╣я┬п╣п╫п╦п╧/LAN. - 1999. - б╘11.
2. п╜п╧п╫п╢п╤п╣п╩ D. XML: п╡я─п╣п╪я▐ п©я─п╦я┬п╩п╬// п√я┐я─п╫п╟п╩ я│п╣я┌п╣п╡я▀я┘ я─п╣я┬п╣п╫п╦п╧/LAN. - 1999. - б╘11.
3. Tidwell D. XSLT. - O'Reilly & Associates, 2001.